In this page, you can find audio samples of performances synthesized by our DDSP-based piano synthesizer.
Overview
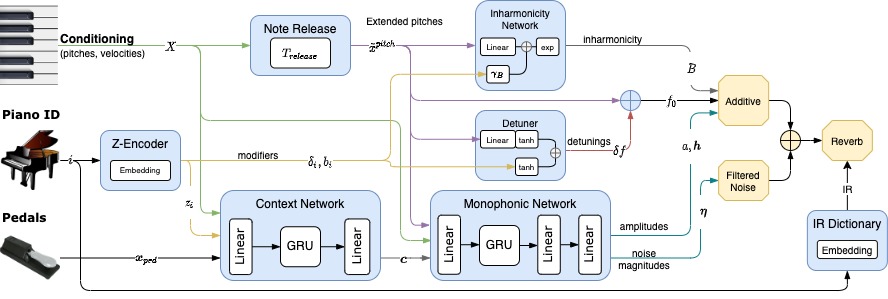
Full architecture of the proposed piano sound synthesizer. The blue boxes represent the trained modules for the control of the synthesizers.
The differentiable synthesizers from DDSP are represented by yellow boxes (Additive, Filtered Noise and Reverberation).
Synthesis examples
The MIDI performances are taken from the test set of the MAESTRO dataset.
Benchmark systems include:
Original recording: the real audio recording of the performance.
TTS: a neural-based synthesis model inpired by text-to-speech techniques.
Different configurations of our DDSP-based model are also compared:
Default: the default configuration illustrated previously.
No Fine-tuning: without applying the fine-tuned parameters of the detuner and inharmonicity sub-models.
Deep-Inharmonicity: replacing the explicit inharmonicity sub-model by a deep neural network.
Reduced-Context: remove the polyphonic information from the context computation.
2009-only: model trained solely on the 2009 piano model.
A. Scriabin - Etude, Op.42 No.4
Piano year: 2009
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
C. Debussy - Etude, No.7 “Study in Chromatic Steps”
Piano year: 2004
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
D. Scarlatti - Sonata in D Major, K.118
Piano year: 2014
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
F. Mendelssohn - Fantasy in F-sharp minor, Op.28
Piano year: 2017
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
F. Liszt - Hungarian Rhapsody No.9 in E-Flat Major, S.244
Piano year: 2015
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
F. Schubert - Impromptu Op.142 No.4, in F minor, D935
Piano year: 2011
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
F. Chopin - Nocturne in B Major, Op.9 No.3
Piano year: 2009
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
J.S. Bach - Prelude & Fugue in G-Sharp Minor, WTC I BWV.863
Piano year: 2013
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
L. van Beethoven - Rondo a Capriccioso “Rage over a Lost Penny”, Op.129
Piano year: 2018
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
S. Rachmaninoff, Etudes-Tableaux, Op.39 No.9
Piano year: 2006
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
W.A. Mozart - Sonata in B-Flat Major (1st movement), K333
Piano year: 2008
Model
Audio sample
Original recording
Fluidsynth
Pianoteq
TTS
Default
No Fine-tuning
Deep-Inharmonicity
Reduced-Context
2009-only
Bonus: Modular Decomposition
As in the original DDSP experiments, the audio output of the differentiable DSP layers can be heard.
The audio without reverb can be extracted before applying the reverberation layer:
Wet audio
Reverb removed
Audio can also be decomposed into its pure harmonic components and the residual noise, by only listening to the outputs of the additive and filtered noise synthesizers: